Appearance
Python 实战:对 Excel 中的学生按成绩排序
要求
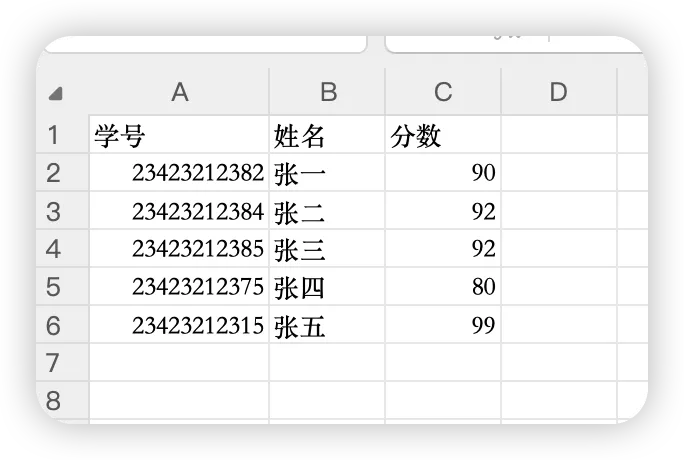
excel 文件 source.xlsx 记录了某班级学生的语文成绩,文件内容有表头,除表头外,一行对应一个学生,每一行有三个字段,分别是学号、姓名、分数。
现在需要:
1,生成上述 excel 文件。
2,检查文件中有没有出现重复的学号,检查学号是不是都是数字。
3,对学生成绩进行排序,按照分数从大到小排序,如果分数一样,则按照学号从大到小排序。排序结果写到excel文件 sort_result.xlsx 中。排序结果中保留表头。
实现
安装依赖
pip3 install openpyxl --user注意有些操作系统是命令是 pip。
生成 excel 文件
文件名:create_excel.py 。内容:
py
from openpyxl import Workbook # 从openpyxl库导入创建操作Excel类
def create_correct_excel(): # 创建正确格式的Excel文件
wb = Workbook()
ws = wb.active
ws.title = "学生成绩"
ws['A1'] = '学号' # 写入表头
ws['B1'] = '姓名'
ws['C1'] = '分数'
students = [
['23423212382', '张一', 90], # 学生数据
['23423212384', '张二', 92],
['23423212385', '张三', 92],
['23423212375', '张四', 80],
['23423212315', '张五', 99]
]
for i, student in enumerate(students, start=2): # 写入数据
ws[f'A{i}'] = student[0]
ws[f'B{i}'] = student[1]
ws[f'C{i}'] = student[2]
wb.save('source.xlsx') # 保存数据
print("source.xlsx 文件创建成功!")
if __name__ == "__main__":
create_correct_excel()执行后会有 source.xlsx 文件生成。
成绩排序
文件名:student_sorter.py 。内容:
python
import openpyxl
from openpyxl import Workbook # 导入整个openpyxl库,以读取Excel文件
def process_student_grades():
source_file = "source.xlsx" # 定义源文件名
print("开始处理学生成绩数据...")
print(f"读取源文件: {source_file}")
try: # 异常处理机制,防止程序崩溃
wb = openpyxl.load_workbook(source_file)
sheet = wb.active
print("文件读取成功")
except FileNotFoundError:
print(f"错误:找不到文件 {source_file}")
print("请确保source.xlsx文件存在于当前目录")
return
except Exception as e:
print(f"读取文件时出错:{e}")
return
students = [] # 存储所有学生数据
student_ids = set() # 检查重复学号
has_duplicate = False # 标志变量
has_non_numeric_id = False # 标志变量
print("\n开始检查数据...")
for row in range(2, sheet.max_row + 1): # 跳过表头
student_id = sheet.cell(row=row, column=1).value # 获取单元格值
name = sheet.cell(row=row, column=2).value
score = sheet.cell(row=row, column=3).value
if student_id is None or name is None or score is None: # 检查是否为空行
continue
print(f"处理学生: 学号={student_id}, 姓名={name}, 分数={score}")
if not str(student_id).isdigit(): # 检查学号是否全为数字
has_non_numeric_id = True
print(f"警告:学号 '{student_id}' 不是纯数字")
if student_id in student_ids: # 检查学号是否重复
has_duplicate = True
print(f"警告:学号 '{student_id}' 重复")
else:
student_ids.add(student_id)
student = { # 创建学生字典
'student_id': student_id,
'name': name,
'score': score
}
students.append(student)
print("\n" + "=" * 50) # 检查结果
print("数据检查结果:")
if not has_duplicate:
print("没有重复的学号")
else:
print("存在重复学号")
if not has_non_numeric_id:
print("所有学号都是数字")
else:
print("存在非数字学号")
print("=" * 50)
print("\n开始排序数据...")
students_sorted = sorted(students, key=lambda x: (-x['score'], -int(x['student_id']))) # 主要按分数降序,分数相同时按学号降序
result_wb = Workbook() # 创建新工作簿
result_sheet = result_wb.active
result_sheet.title = "排序结果" # 设置工作表名称
result_sheet['A1'] = '学号' # 写入数据
result_sheet['B1'] = '姓名'
result_sheet['C1'] = '分数'
for index, student in enumerate(students_sorted, start=2): # 写入排序后的数据
result_sheet.cell(row=index, column=1, value=student['student_id'])
result_sheet.cell(row=index, column=2, value=student['name'])
result_sheet.cell(row=index, column=3, value=student['score'])
result_file = "sort_result.xlsx" # 保存文件
result_wb.save(result_file)
print(f"排序结果已保存到: {result_file}")
print("\n排序结果预览:") # 在控制台显示排序后的结果
print("学号\t\t\t姓名\t分数") # 对齐输出
print("-" * 40)
for student in students_sorted:
print(f"{student['student_id']}\t{student['name']}\t{student['score']}")
print(f"\n处理完成!共处理了 {len(students)} 名学生数据")
if __name__ == "__main__": # 只有当文件被直接运行时才执行
process_student_grades()执行后会有 sort_result.xlsx 文件生成,点击查看符合预期。